如果说波士顿动力的翻跟头是在帮机器人锻炼筋骨,那么知识图谱的“绘制”则是在试图“创造”一个能运转的机器人大脑。
“目前,还不能做到让机器理解人的语言。”中国科学院软件所研究员、中国中文信息学会副理事长孙乐说。无论是能逗你一乐的Siri,还是会做诗的小冰,亦或是会“悬丝诊脉”的沃森,它们并不真正明白自己在做什么、为什么这么做。
让机器学会思考,要靠“谱”。这个“谱”被称为知识图谱,意在将人类世界中产生的知识,构建在机器世界中,进而形成能够支撑类脑推理的知识库。
为了在国内构建一个关于知识图谱的全新产学合作模式,知识图谱研讨会日前召开,来自高校院所的研究人员与产业团队共商打造全球化的知识图谱体系,建立世界领先的人工智能基础设施的开拓性工作。
技术原理:把文本转化成知识
“对于‘姚明是上海人’这样一个句子,存储在机器里只是一串字符。而这串字符在人脑中却是‘活’起来的。”孙乐举例说。比如说到“姚明”,人会想到他是前美职篮球员、“小巨人”、中锋等,而“上海”会让人想到东方明珠、繁华都市等含义。但对于机器来说,仅仅说“姚明是上海人”,它不能和人类一样明白其背后的含义。机器理解文本,首先就需要了解背景知识。
那如何将文本转化成知识呢?
“借助信息抽取技术,人们可以从文本中抽取知识,这也正是知识图谱构建的核心技术。”孙乐说,目前比较流行的是使用“三元组”的存储方式。三元组由两个点、一条边构成,点代表实体或者概念,边代表实体与概念之间的各种语义关系。一个点可以延伸出多个边,构成很多关系。例如姚明这个点,可以和上海构成出生地的关系,可以和美职篮构成效力关系,还可以和2.26米构成身高关系。
“如果这些关系足够完善,机器就具备了理解语言的基础。”孙乐说。那么如何让机器拥有这样的“理解力”呢?
“上世纪六十年代,人工智能先驱麻省理工学院的马文·明斯基在一个问答系统项目SIR中,使用了实体间语义关系来表示问句和答案的语义,剑桥语言研究部门的玛格丽特·玛斯特曼在1961年使用Semantic Network来建模世界知识,这些都可被看作是知识图谱的前身。”孙乐说。
随后的Wordnet、中国的知网(Hownet)也进行了人工构建知识库的工作。
“这里包括主观知识,比如社交网站上人们对某个产品的态度是喜欢还是不喜欢;场景知识,比如在某个特定场景中应该怎么做;语言知识,例如各种语言语法;常识知识,例如水、猫、狗,教人认的时候可以直接指着教,却很难让计算机明白。”孙乐解释,从这些初步的分类中就能感受到知识的海量,更别说那些高层次的科学知识了。
构建方式:从手工劳动到自动抽取
“2010年之后,维基百科开始尝试‘众包’的方式,每个人都能够贡献知识。”孙乐说,这让知识图谱的积累速度大大增加,后续百度百科、互动百科等也采取了类似的知识搜集方式,发动公众使得“积沙”这个环节的时间大大缩短、效率大大增加,无数的知识从四面八方赶来,迅速集聚,只待“成塔”。
面对如此大量的数据,或者说“文本”,知识图谱的构建工作自然不能再手工劳动,“让机器自动抽取结构化的知识,自动生成‘三元组’。”孙乐说,学术界和产业界开发出了不同的构架、体系,能够自动或半自动地从文本中生成机器可识别的知识。
孙乐的演示课件中,有一张生动的图画,一大摞文件纸吃进去,电脑马上转化为“知识”,但事实远没有那么简单。自动抽取结构化数据在不同行业还没有统一的方案。在“百度知识图谱”的介绍中这样写道:对提交至知识图谱的数据转换为遵循Schema的实体对象,并进行统一的数据清洗、对齐、融合、关联等知识计算,完成图谱的构建。“但是大家发现,基于维基百科,结构化半结构化数据挖掘出来的知识图谱还是不够,因此目前所有的工作都集中在研究如何从海量文本中抽取知识。”孙乐说,例如谷歌的Knowledge Vault,以及美国国家标准与技术研究院主办的TAC-KBP评测,也都在推进从文本中抽取知识的技术。
在权威的“知识库自动构建国际评测”中,从文本中抽取知识被分解为实体发现、关系抽取、事件抽取、情感抽取等4部分。在美国NIST组织的TAC-KBP中文评测中,中科院软件所—搜狗联合团队获得综合性能指标第3名,事件抽取单项指标第1名的好成绩。
“我国在这一领域可以和国际水平比肩。”孙乐介绍,中科院软件所提出了基于Co-Bootstrapping的实体获取算法,基于多源知识监督的关系抽取算法等,大幅度降低了文本知识抽取工具构建模型的成本,并提升了性能。
终极目标:将人类知识全部结构化
《圣经·旧约》记载,人类联合起来兴建希望能通往天堂的高塔——“巴别塔”,而今,创造AI的人类正在建造这样一座“巴别塔”,帮助人工智能企及人类智能。
自动的做法让知识量开始形成规模,达到了能够支持实际应用的量级。“但是这种转化,还远远未达到人类的知识水平。”孙乐说,何况人类的知识一直在增加、更新,一直在动态变化,理解也应该与时俱进地体现在机器“脑”中。
“因此知识图谱不会是一个静止的状态,而是要形成一个循环,这也是美国卡耐基梅隆大学等地方提出来的Never Ending Learning(学无止境)的概念。”孙乐说。
资料显示,目前谷歌知识图谱中记载了超过35亿事实;Freebase中记载了4000多万实体,上万个属性关系,24亿多个事实;百度百科记录词条数1000万个,百度搜索中应用了联想搜索功能。
“在医学领域、人物关系等特定领域,也有专门的知识图谱。”孙乐介绍,Kinships描述人物之间的亲属关系,104个实体,26种关系,10800个事实;UMLS在医学领域描述了医学概念之间的联系,135个实体,49种关系,6800个事实。
“这是一幅充满美好前景的宏伟蓝图。”孙乐说,知识图谱的最终目标是将人类的知识全部形式化、结构化,并用于构建基于知识的自然语言理解系统。
尽管令业内满意的“真正理解语言的系统”还远未出现,目前的“巴别塔”还只是在基础层面,但相关的应用已经显示出广阔的前景。例如,在百度百科输入“冷冻电镜”,右竖条的关联将出现“施一公”,输入“撒币”,将直接在搜索项中出现“王思聪”等相关项。其中蕴含着机器对人类意图的理解。
“知识图谱的应用涉及到众多行业,尤其是知识密集型行业,目前关注度比较高的领域:医疗、金融、法律、电商、智能家电等。”孙乐介绍,基于信息、知识和智能形成的闭环,从信息中获取知识,基于知识开发智能应用,智能应用产生新的信息,从新的信息中再获取新的知识,不断迭代,就可以不断产生更加丰富的知识图谱,更加智能的应用。
-

浙江杭州夫妻醉酒老公床上酣睡妻子倒挂窗外 提醒:理性饮酒安全第一
头条 22-01-21
-

美国爸爸辅导孩子写汉字气到崩溃一行字写了3小时!网友:这跟国籍无关
头条 22-01-20
-

绝望! 女子隔离14天通过监控看狗子把家拆完 网友:感到“崩溃”
头条 22-01-20
-
辽宁沈阳男子冬天醉卧路边冻掉4根手指!网友:多亏被人发现
头条 22-01-18
-

重庆一孕妇剪毁婚庆店内32件婚纱礼服当事人发文
头条 22-01-17
-

中国空间站与国际空间站一张对比图火了 网友直呼:画面引起舒适
头条 22-01-13
-

辟谣!800多人被拉定边沙漠去隔离?西安网警:假的!
头条 22-01-11
-

生日蛋糕上插满课本男孩崩溃大哭 妈妈:想提醒他好好复习
头条 22-01-11
-

男子地铁摸女性屁股被扇3分钟耳光?警方通报
头条 22-01-06
-

天津高速现驼鸟奔跑 官方回应:系车主运输途中不慎掉落已被车主领回
头条 22-01-05
-

长得挺特别!菠萝味草莓一斤150元 网友:直接买个菠萝吃不好吗
头条 22-01-05
-

“秦始皇”做核酸珍贵画面流出?逗乐网友!调侃:“秦始皇也要核酸了!”
头条 21-12-31
-

985大学硕士妈妈吐槽儿子是学渣:他爸气得2次心梗!以后只希望孩子健康成长
头条 21-12-31
-

查干湖“头鱼”拍出299.9999万的天价!网友:怎么吃才体现它的身价
头条 21-12-29
-

村主任用洒水车向摊位喷水?官方回应:责令其辞去村委会主任职务
头条 21-12-27
-
“外教辱骂防疫人员”,西安警方回应:已成立工作专班进行调查
头条 21-12-27
-

破防了!91岁奶奶和8岁猫咪的对话让人泪崩 网友:祝愿老人健康长寿
头条 21-12-23
-

5岁女童配合消防员教科书式自救 网友点赞:很勇敢!
头条 21-12-23
-

大爷被困电梯淡定唠嗑等救援 网友:为大爷的冷静沉着点赞!
头条 21-12-22
-

男子4万元存款18年后却被银行告知存款已被支取仅剩10块钱 法院:银行赔!
头条 21-12-20
-

深圳一男子加油站拔油枪点燃后逃跑 警方已介入调查纵火人员已锁定
头条 21-12-17
-

这位感动千万抖音网友的河南“留虾女孩” 入选央视年度短片《2021看见笑容》
头条 21-12-17
-

泪目!95岁妈妈病床前亲吻74岁生病的女儿 网友:孩子不管多大都是妈妈的宝贝
头条 21-12-15
-

川妹子抽中50颗榴莲直呼吃不完!网友:可以共享你的负担吗?
头条 21-12-15
-
河南省政府发布2022年元旦放假通知
头条 21-12-15
-
濮阳市聚碳新材料产业联盟成立
头条 21-12-15
-
周口机场预计什么时候建好?都有到哪些城市的航线?官方回复来了
头条 21-12-15
-
预计明年超50家企业回归,瑞银称中概股H股上市将继续升温
头条 21-12-15
-
新乡发现一境外输入奥密克戎病例密接者,活动轨迹公布
头条 21-12-15
-
河南:中药配方颗粒不得在医疗机构以外销售
头条 21-12-15
-
中原环保完成发行5亿元超短融,利率2.95%
头条 21-12-15
-
南阳市政府将与中车四方所在新能源装备等领域开展深入合作
头条 21-12-15
-
郑州出台新措施:公租房可“掌上”缴租秒办理
头条 21-12-15
-
国家统计局:11月社会消费品零售总额增长3.9%
头条 21-12-15
-
中国11月规上工业增加值同比增长3.8%
头条 21-12-15
-
1207万!全年就业超额完成预期目标
头条 21-12-15
-
河南凯旺科技公开发行2396万股新股,获6321.47倍申购
头条 21-12-15
-
事关货币政策、房地产、全面注册制,一行两会划定明年工作重点
头条 21-12-15
-
隔夜欧美·12月15日
头条 21-12-15
-
多部委密集部署明年工作!三大看点值得关注
头条 21-12-15
-
立方风控鸟·早报(12月15日)
头条 21-12-15
-
医药巨头今日登陆科创板!高瓴重仓"陪伴",引入"绿鞋"机制
头条 21-12-15
-
皮海洲:临门一脚踏刹车!龙竹科技终止转板说明了什么
头条 21-12-15
-
立方风控鸟·晚报(12月14日)
头条 21-12-14
-
成渝地区双城经济圈建设2022年拟推进160个重大项目,投资约2万亿元
头条 21-12-14
-
总投资额超百亿!中建七局接连中标两个EPC总承包项目
头条 21-12-14
-
2022年部分地方债提前下达,财政提前发力稳经济
头条 21-12-14
-
信阳华信投资集团10亿元中票完成发行,利率3.70%
头条 21-12-14
-
新强联拟择机出售所持明阳智能股票
头条 21-12-14
-
洛阳新强联拟亿元入股山东拟IPO公司,持股4.50%
头条 21-12-14
-
焦作在这场推介会上现场签约28个项目,总投资240亿元
头条 21-12-14
-
河南7种轻微交通违法可免罚
头条 21-12-14
-

广州高校发现古墓考古专业出动!网友:这不巧了嘛!毕业论文自己找来了
头条 21-12-14
-

浙江乐清民警自曝37岁未婚救下轻生女子 网友:一定要最爱自己
头条 21-12-14
-

画面感太强!主人出差猫咪打开水龙头把家淹了 网友:当然是原谅它
头条 21-12-09



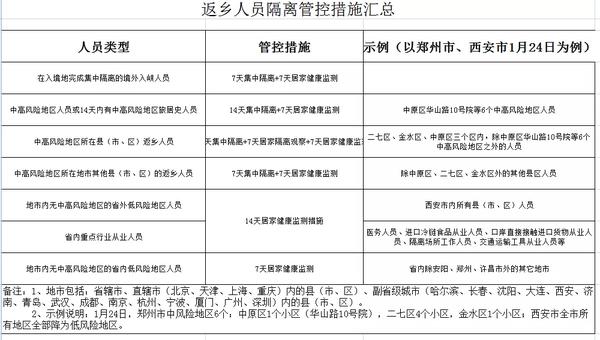






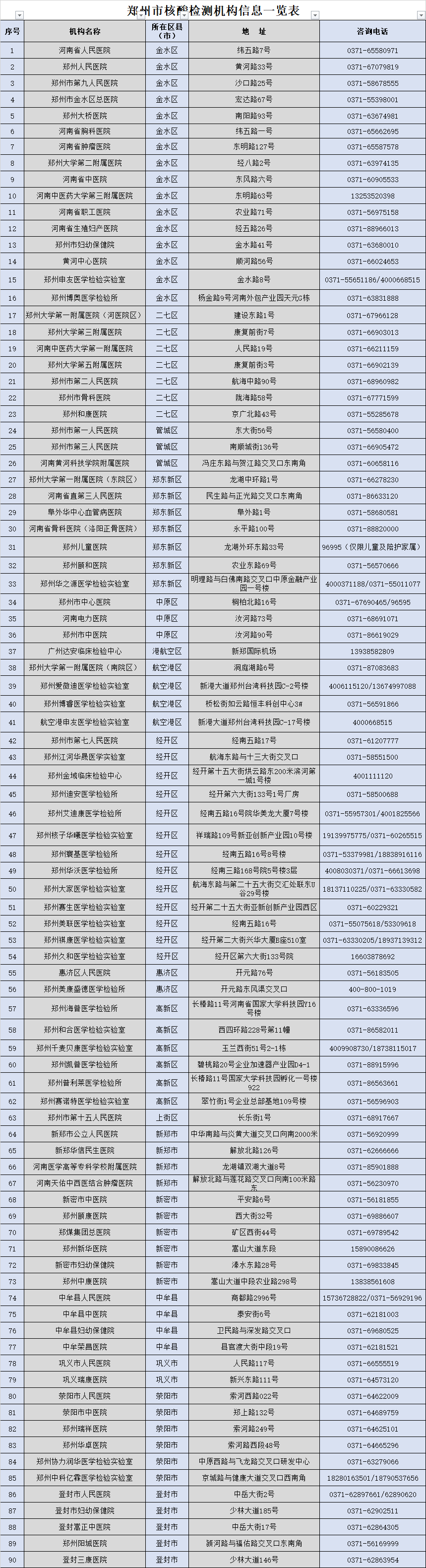































































- 加盟大平台,继往又开来!怡亚通全球招募合2022-01-25
- 伊利新春迷你剧《我耀我家》:关于春节和冬2022-01-25
- 360金融课堂学员:误入杀猪盘后的重生与成长2022-01-25
- 2021年全国海关查扣进出口侵权嫌疑货物7.92022-01-25
- 相约冰雪,一起来丨逐梦前行2022-01-25
- 国家卫健委:昨日新增确诊病例45例 其中本2022-01-25
- 相约冰雪,一起来|以中国速度完成冰雪运动2022-01-25
- 超全科普!一次看懂北京冬奥15个比赛项目2022-01-25
- 本次疫情郑州共开展了十轮全员核酸检测 共2022-01-25
- 噪声污染防治法将于2022年6月5日施行2022-01-25
- 扩散!疫情期间血透预约平台在郑好办App上2022-01-25
- 速看!三门峡:返乡人员隔离管控措施汇总2022-01-25
- 官方回应:关于禹州市一高一学生反映不能返2022-01-25
- 今年将建30家河南省科普基地 提升广大公众2022-01-25
- 春节前郑州有望全域“低风险” 1月25日起2022-01-25
- 周口郑州新生儿登记排全国前十 王李张等222022-01-25
- 洛阳全面深入推动县管校聘改革 800多所中2022-01-25
- 2022年度一次性工亡补助金标准确定 调整为2022-01-25
- 请乘坐合规车辆!这些网约车非法营运被查处2022-01-25
- 河南:26至28日多地仍有大到暴雪局部暴雪2022-01-25
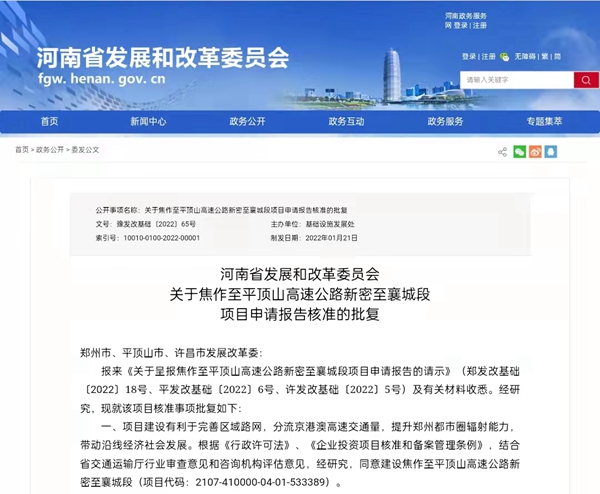
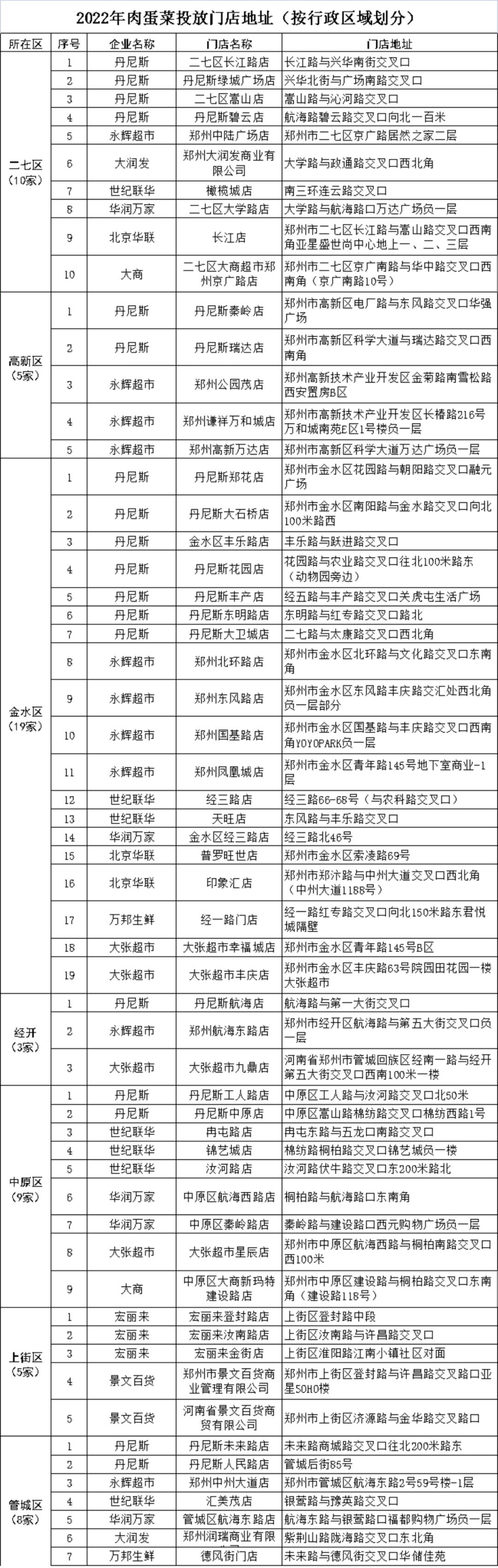
- 郑州市政府投放储备肉蛋菜 市民购买热情高2022-01-25
- 春节即将来临 郑州市全面禁售禁放烟花爆竹2022-01-25
- 郑州发布2022年32号通告:部分区域疫情风险2022-01-25
- 河南出台“十四五”期间系列养老服务体系“2022-01-25
- 春节前河南将出现一轮长时间大范围的中度至2022-01-25
- 郑州预计除夕前全域降为低风险 春运期间人2022-01-25
- 郑州行程卡何时摘星?调整风险等级及区域解2022-01-25
- 春运期间人员返郑离郑防控政策来了 返郑人2022-01-25
- 郑州发布31号通告:9个城区开展新冠病毒核2022-01-25
- 郑州已解除封控管控隔离群众 可根据病情需2022-01-25










